Query the optimized data
Crawl transformed data, configure permissions and run queries
We can now configure a Glue crawler to examine the newly written files and create a table in the catalog for us. Once the table is created in the Glue catalog, we will configure Lake Formation permissions to allow our user (lf-admin) to read from this table. We can then use Athena to run queries on the transformed dataset.
In the AWS management console, navigate to the AWS Glue service.
On the left-hand side, click on Crawlers, and then Add crawler
Provide a unique name for Crawler name, such as
Transformed customer data crawler, then click NextFor Specify crawler source type, leave Data stores selected and click Next
For Add a data store, under Include path, click the folder icon and then expand the bucket starting with lf-data-lake-bucket-, expand the prefix transformed, then click the selector next to customers and click on Select
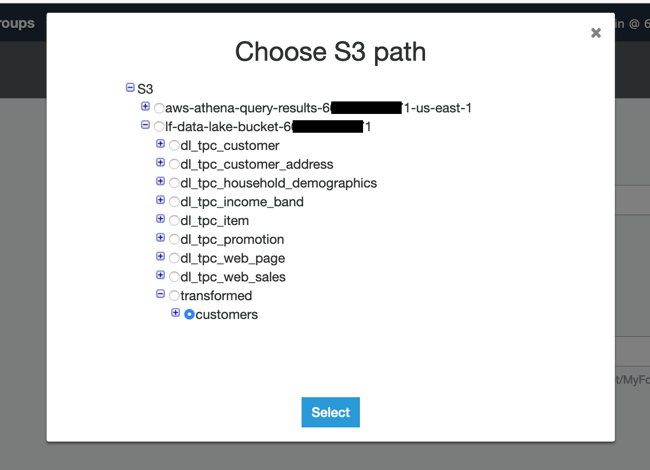
Do not specify any Exclude patterns, just click Next
For Add another data store, leave No selected and click Next
For Choose an IAM Role, select Choose an existing IAM role, and from the drop-down select LF-GlueServiceRole then click Next
For Frequency, leave Run on demand selected and click Next
On the Configure the crawler’s output for Database select tpc, and then click Next
Review the summary information, and then click Finish
On the Crawlers page select the checkbox for your newly created crawler (such as Transformed customer data crawler) and then click Run crawler
Once the crawler has completed running, we need to add Lake Formation permissions on this table, so navigate to the Lake Formation service in the AWS management console.
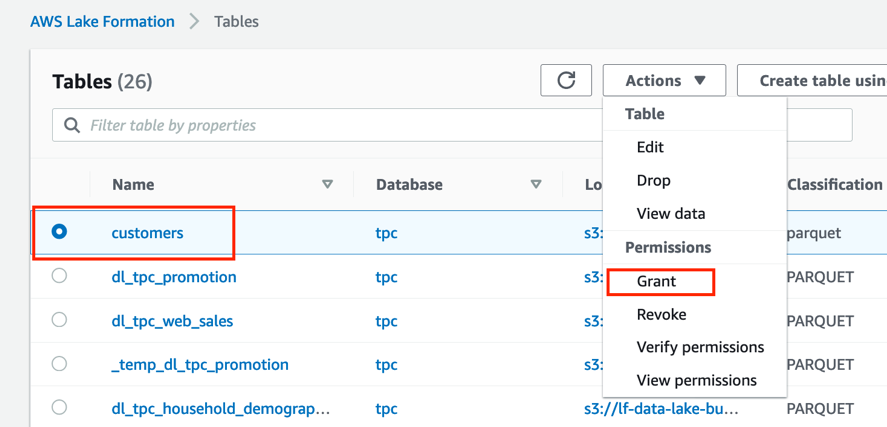
On the left-hand side click on Tables, and then click the selector next to the customers table and click Actions / Grant.
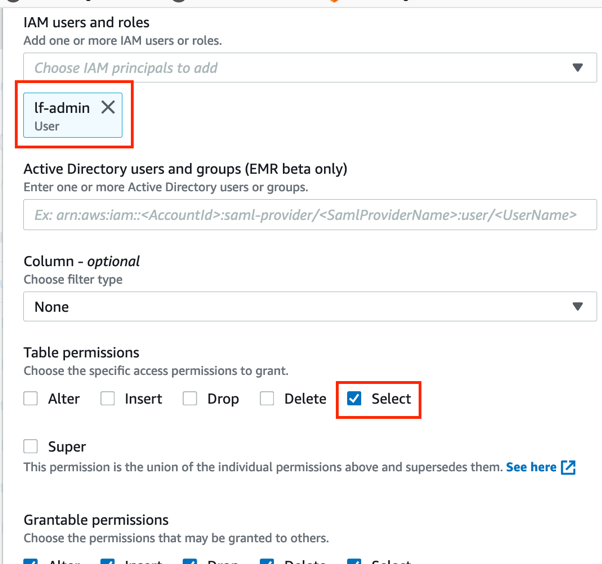
For IAM users and roles, select lf-admin and for Table permissions mark the tick box for Select permissions and then click Grant
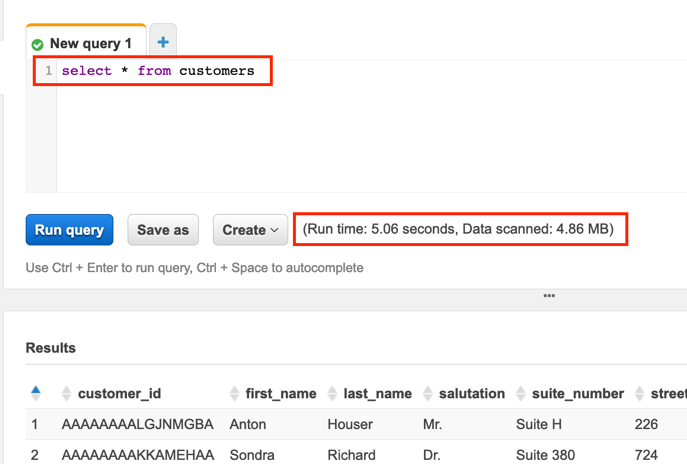
Navigate to the Athena service in the AWS management console and run the following query:
select * from customersNote the amount of data scanned and the time it takes to run.
Now you can run the following optimized query which selects only the specific columns our marketing department needs for their campaign (name and email address) and targets a specific state and location type.
select first_name, last_name, salutation, email_address from customers where state like 'TX' and location_type like 'condo'With this query Athena needs to read less data as we have specified columns (and Parquet files are column optimized), and Athena only needs to read the files in the S3 prefixes that match our WHERE clause because we partitioned our data by state and location type.
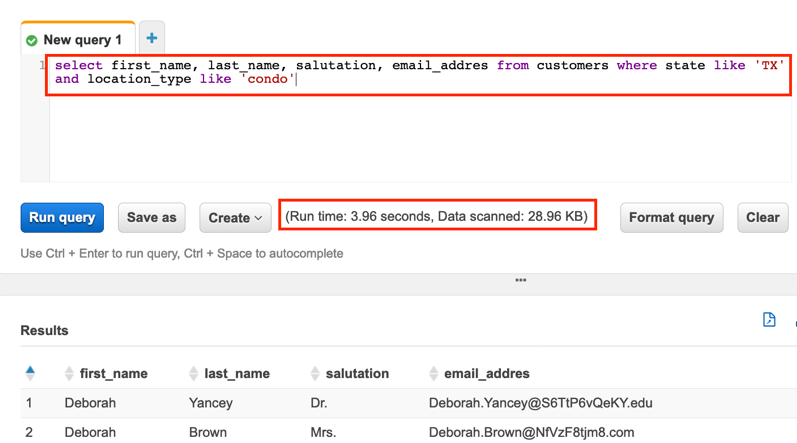
By selecting the specific columns we needed, and by querying with a WHERE clause that matched our partitioning structure, the amount of data scanned was less than 1% of the original select * query. In this lab we are working with a very small dataset, but this illustrates the type of performance improvement that you could achieve on much larger datasets by using optimized file formats and partitioning.