Configure S3 Event Trigger
Configure S3 bucket for Event Trigger
In this section we will configure an event trigger on our S3 Raw bucket that will run an AWS Lambda function whenever new objects are created in the bucket.
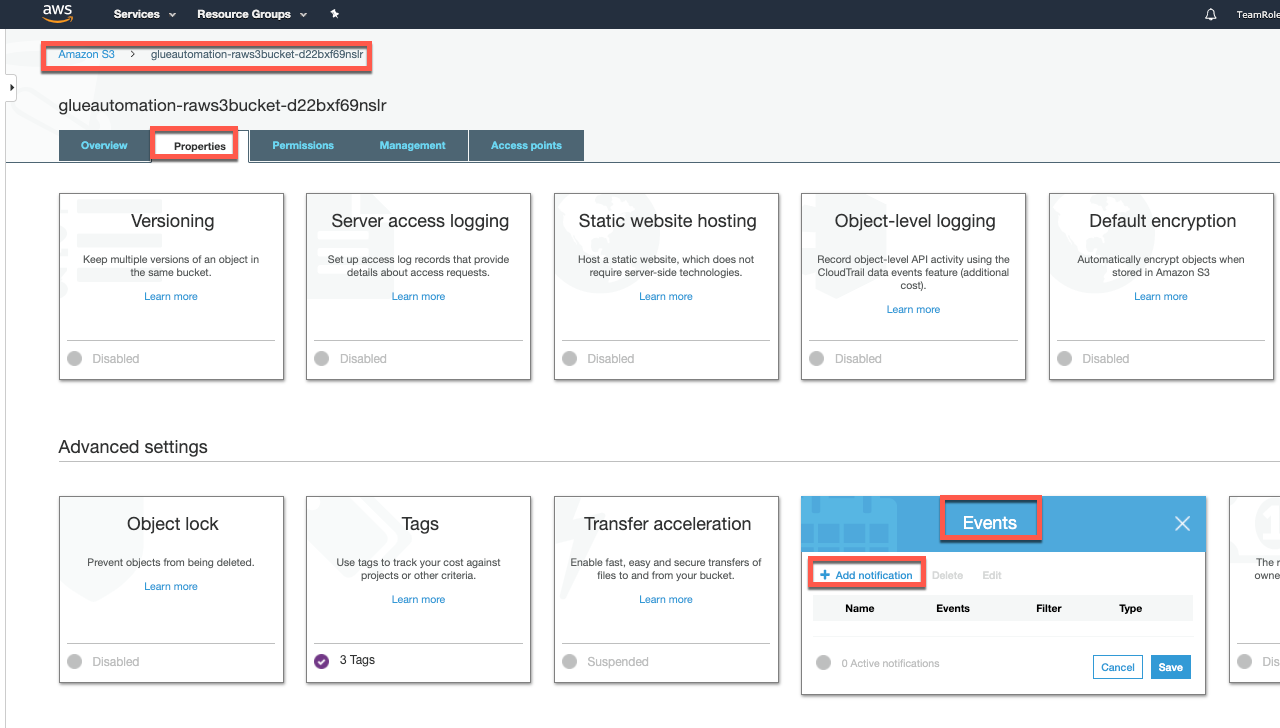
Navigate to the Amazon S3 service, and select S3 Raw bucket (Note:
<stackname>-raws3bucket in it’s name)- Select Properties
- Under Properties highlight Events
- Click Add Notification
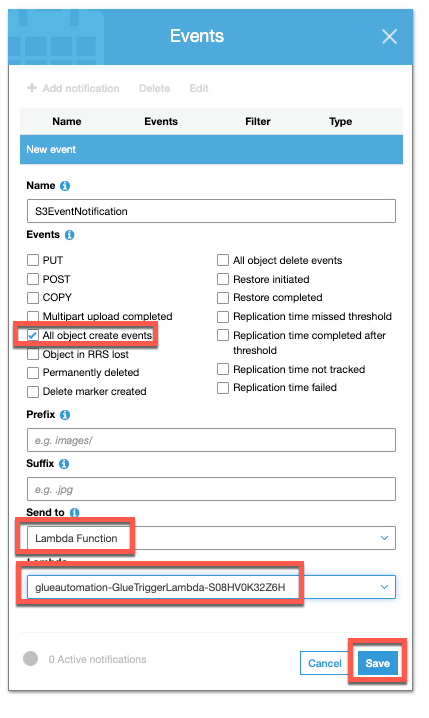
Configure Notification:
- Name - Provide a name of your choice (e.g.S3eventNotification)
- Event - Select “All object create events”
- Leave Prefix and Suffix as default
- Send to - Select Lambda function
- Lambda - From dropdown option, select Lambda function which has GlueTriggerLambda in its name. This function was created as part of Cloudformation depolyment.
The primary purpose of the function is to kick off an AWS Glue catalog job to catalog recently ingested data in S3 Raw bucket, along with re-try logic to send any failed messages from Amazon SQS queue. - Click Save
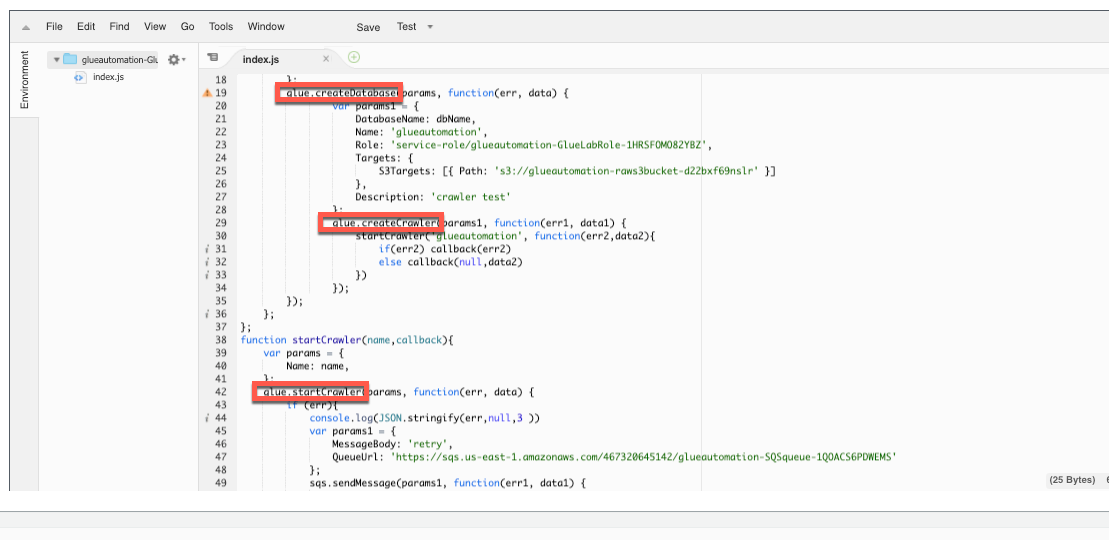
Lambda Function - AWS Glue catalog
Navigate to the AWS Lambda service, select Glue Catalog function (Note: Function would have GlueTrigger in it’s name)
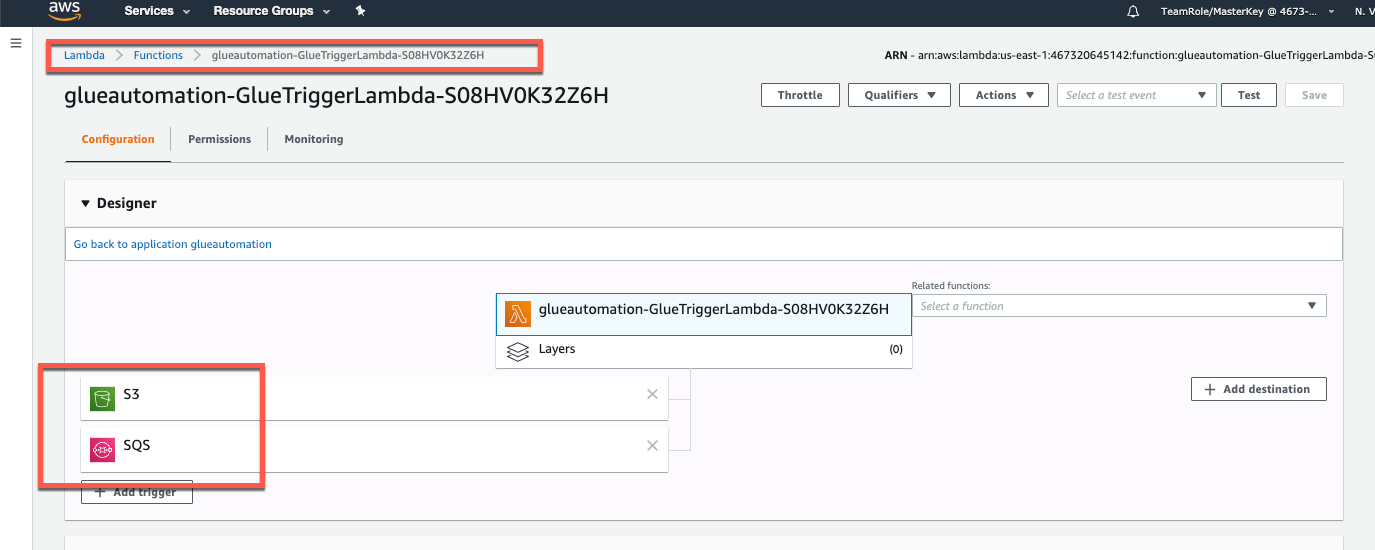
Review the function code. At a high level the code does the following:
- Creates AWS Glue Catalog database based on the name you provided in the CloudFormation template (e.g. glueautomation)
- Configures and kicks-off AWS Glue crawler job to crawl recently added file and extract metadata information from the data
- Configures re-try logic to read failed messages from Amazon SQS queue