Query Data using Athena
In this section we will access the data in our data lake using Amazon Athena and compare the performance of the queries when accessing the same data across different file formats (CSV versus Parquet)
Catalog Parquet format data in the AWS Glue Catalog
Amazon Athena uses the AWS Glue catalog or Apache Hive metastore (beta) as the data catalog. The first step is to catalog the data in the AWS Glue catalog before querying in Athena.
The customer sample data in CSV format is already catalog’ed in AWS Glue as part of the data ingestion process.
In the AWS Glue console navigation pane, check Tables under Databases to confirm the table name

For cataloging the customer sample data in Parquet format, under the AWS Glue console navigation pane click Crawlers and Add Crawler
- Crawler name - Provide a name of your choice (e.g. glueparquet)
- Crawler source type - Select Data stores
- Data store - Select S3 from dropdown menu and specify the path of S3 processed bucket (
<stackname>-processedS3bucket in it’s name). - Select No for adding another data store
- IAM Role - Select Choose an existing IAM role and select
(<stackname>-GlueLabRole)from the drop-down menu. - Frequency - Select the Run on demand option
- Configure crawler output - Select the database name you provided in the Cloudformation input (e.g. glueautomation). Database is listed in the drop-down menu.
- Review all options and click Finish
On the next screen it will prompt to ask if you want to run the newly created crawler job - Select Run it now and watch the execution.

Within a few minutes the crawler job will be completed and once Status shows Ready, review the newly created table by clicking Tables in the navigation pane.

Explore the Parquet table to check the table properties - Number of records, Average Record size and column name and their data types.
Configuring Amazon Athena
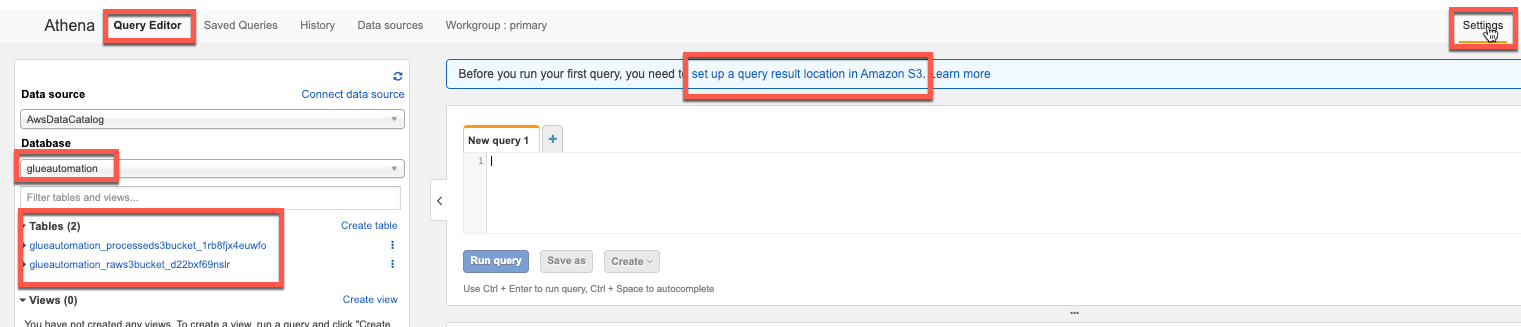
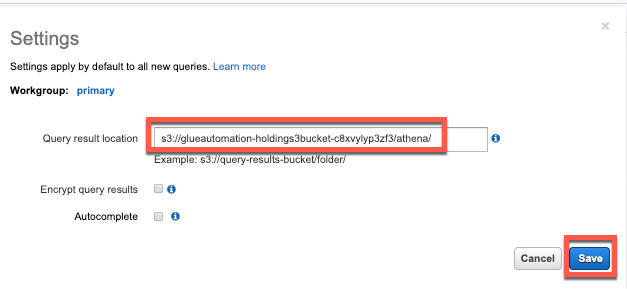
Important: Before using Athena for executing queries, you need to set a query result location. This is the S3 path where results of all queries you run will be stored. If no query results location is specified, the query fails with an error. Refer to this documentation link for more details.
Let’s first create a S3 folder in which our IAM user has write permissions. For this workshop, we will use S3 Holding bucket (
<stackname>-holdingS3bucket in it’s name). Under S3 holding bucket create a folder (e.g. athena) as shown and Click Save.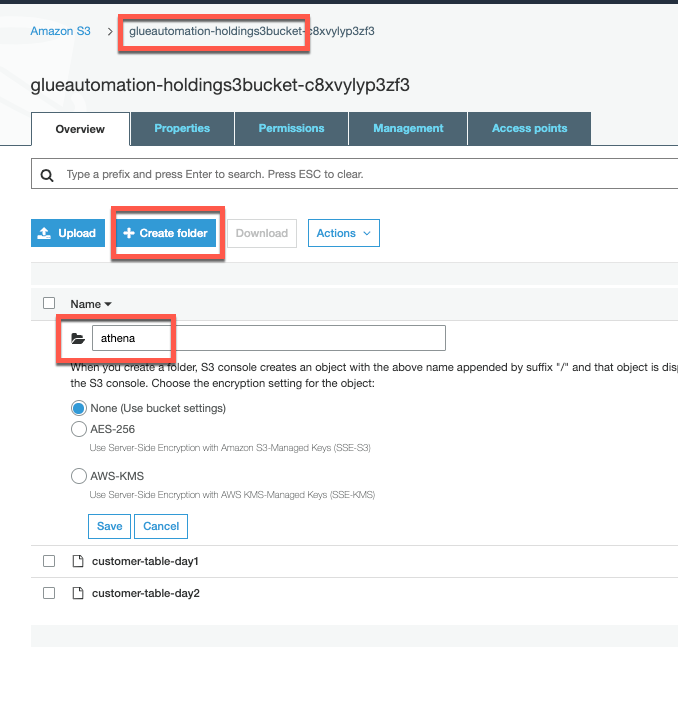
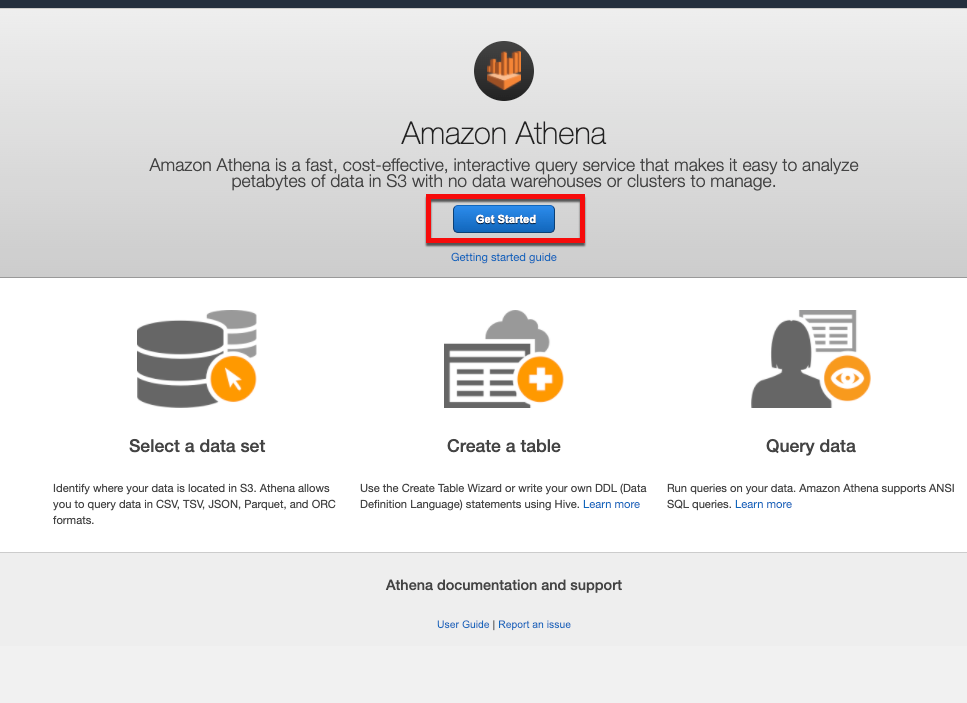
Open the Athena Console which will display the Get started page if you are accessing Athena for the first time. Click Get started to open the full Athena console
On the Athena console Query Editor, select the settings in the top-right corner to specify an S3 location as shown:
Specify the above created S3 bucket / folder and click Save:
Querying data using Amazon Athena
In the Amazon Athena console, select Query Editor and select the database you created earlier (e.g. glueautomation). This should list 2 tables - one referring to CSV data format and another one to Parquet data format.
Note: The table with CSV format has a table name starting with (
<stackname>-raws3bucket), and the table with Parquet format has a table name starting with (<stackname>-processeds3bucket)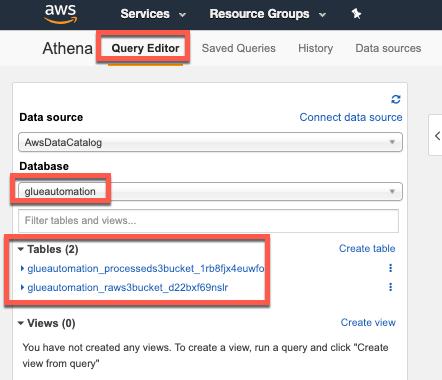
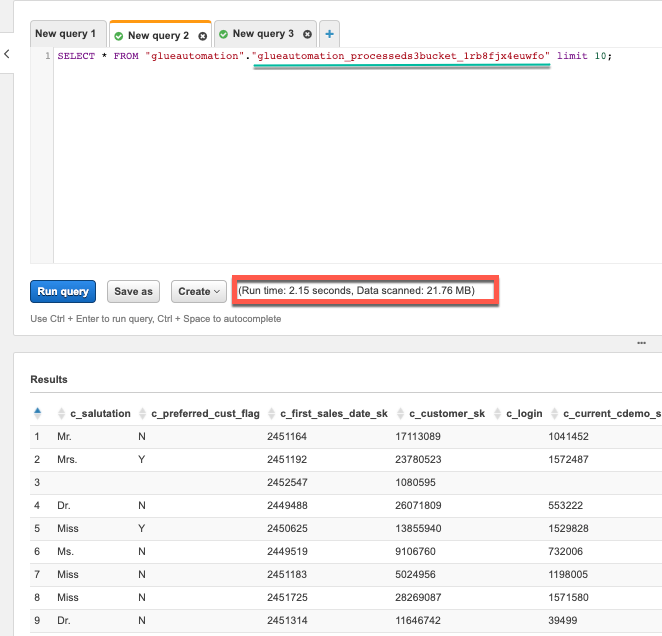
Query 1:
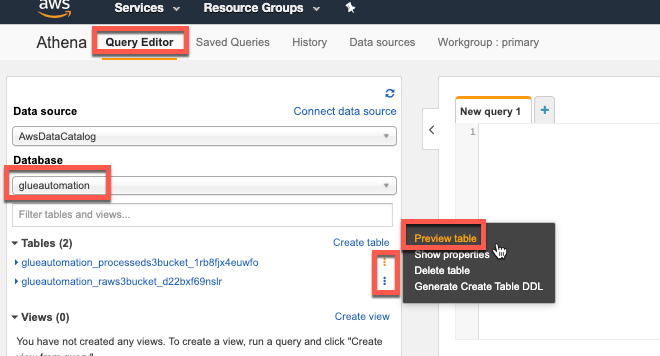
To preview the data click on the 3 dots next to one of the table names and select Preview table. Then do the same step for the other table. This will automatically query a subset of the table and shows the results in separate tabs as shown:
Check out the run time for each query and also the total amount of data scanned. What is your interpretation ??
CSV Format:
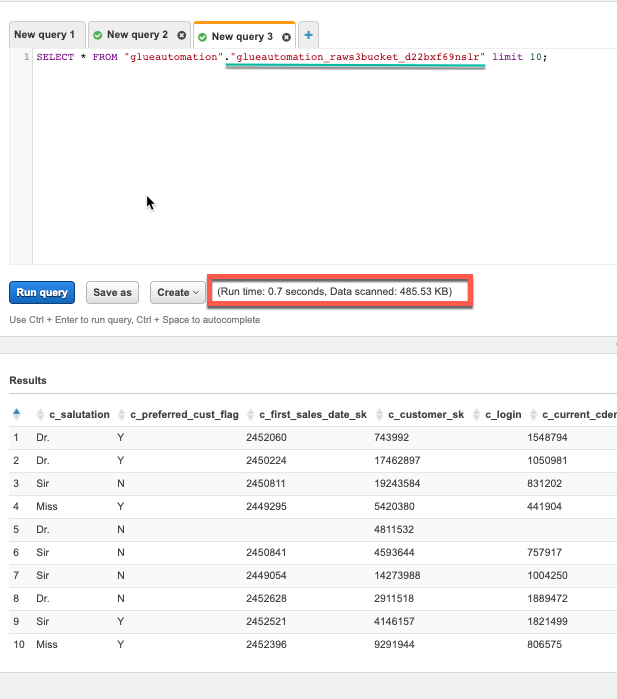
Parquet Format:
Query 2:
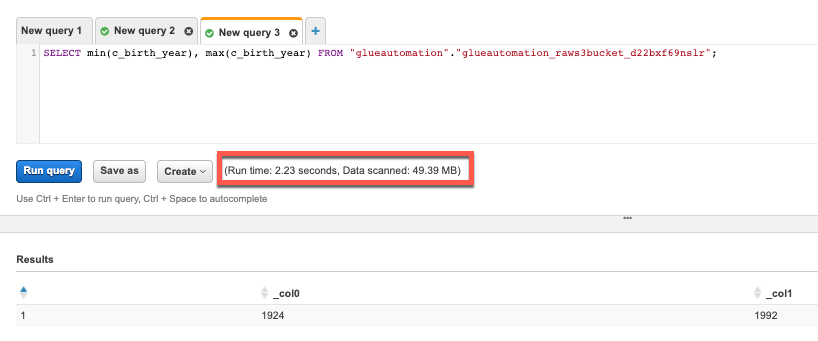
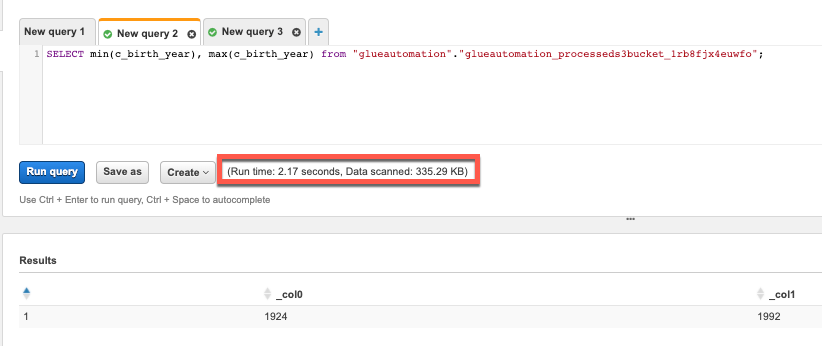
Now let’s try to retrieve distinct, minimum and maximum values of a particular column and see the difference in terms of data scanned and time taken to execute the query.
SELECT min(c_birth_year), max(c_birth_year) FROM "glueautomation"."glueautomation_raws3bucket_d22bxf69nslr";–> Replace database and table name per your setup.Note: DO NOT copy-n-paste query directly from this document into Athena Editor as you might face formatting issues.
CSV Format:
Parquet Format:
Run the following query and interpret the results:
SELECT distinct(c_birth_country) FROM "glueautomation"."glueautomation_raws3bucket_d22bxf69nslr";–> Replace database and table name per your setup.
Query 3:
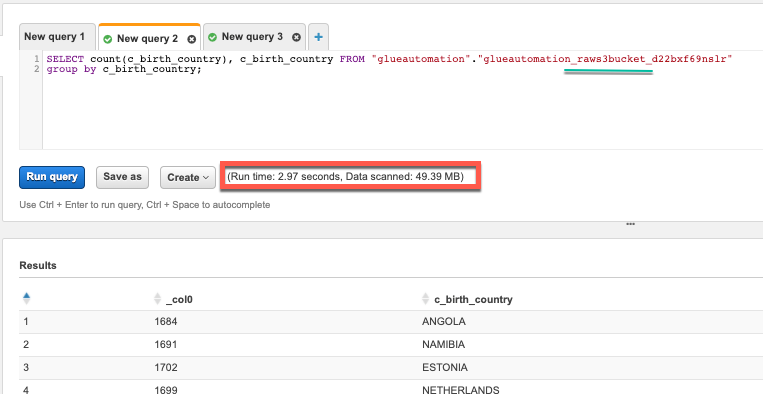
In this query we will try to first perform an individual column operation and subsequently perform a groupby operation to mimic a Datawarehouse query.
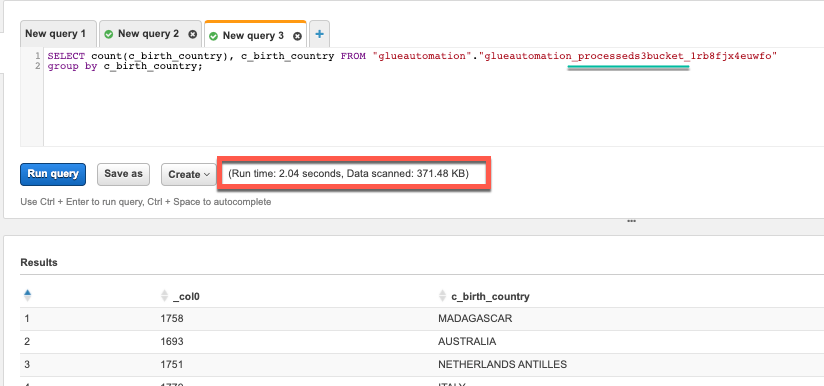
SELECT c_birth_country, count(c_birth_country) FROM "glueautomation"."glueautomation_raws3bucket_d22bxf69nslr" group by c_birth_country;–> Replace database and table name per your setup.
CSV Format:
Parquet Format:
Note:
Amazon Athena provides a serverless interactive SQL query engine and is priced based on the amount of data scanned for each query. As a result it is very important to use the right data format to reduce the query cost and to improve performance.
For reference, in US-East pricing for Athena is $5 per TB of data scanned.