Automate Glue catalog
Automate Data Cataloging with AWS Glue crawler
In this section we will upload a file to S3 to trigger the Lambda function we created (this will start the AWS Glue catalog process to crawl data from S3 Raw bucket). We can then view the cataloged table under AWS Glue Databases.
To automatically kick off AWS Glue crawler job, we will manually copy a file ()customer-table-day-1) from S3 Holding bucket into S3 Raw bucket.
Important - DO NOT copy both the files in the holding bucket as we will be using the second file to test the end-to-end data workflow later.
Navigate to the Amazon S3 service and go to the S3 Holding bucket:
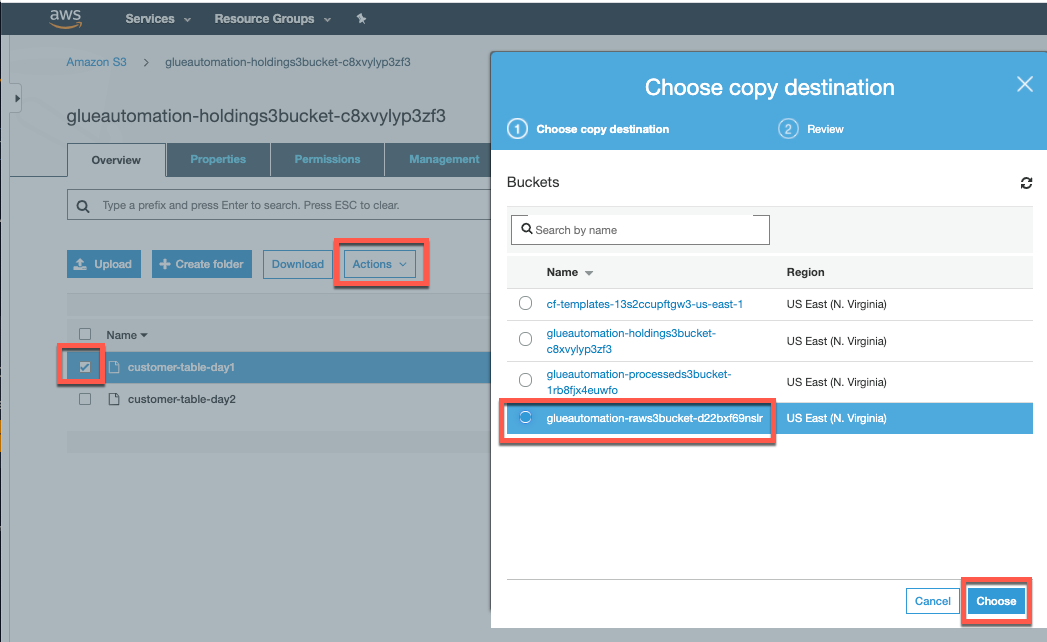
- Select the object “customer-data-day1”
- From the Actions dropdown select “Copy” (note that you may need to scroll down the list of actions to see the copy action)
- For Copy Destination, select the S3 raw bucket (Note: Bucket would have
<stackname>-raws3bucket in it’s name) - Click on the “Choose” button and then the “Copy” button
Once the object is copied into the S3 taw bucket, the event based trigger we configured earlier will call our AWS Lambda function to kick off AWS Glue crawler job to crawl and capture information about recently ingested data.
AWS Glue Catalog
On the AWS Console, navigate to the AWS Glue service. If this is the first time you are accessing the Glue service you will be redirected to the “Get started” page.
Click Get Started to start using the AWS Glue service.
Under the AWS Glue navigation panel, select Crawlers and you should see the new crawler execution with status Starting indicating that the crawler job has been triggered successfully and is starting. At the end of successful execution the Glue crawler will have created a table in the database we specified.
Note: AWS Glue catalog jobs takes approx. 8-10 minutes to run. Good time for a coffee break !! ☕️

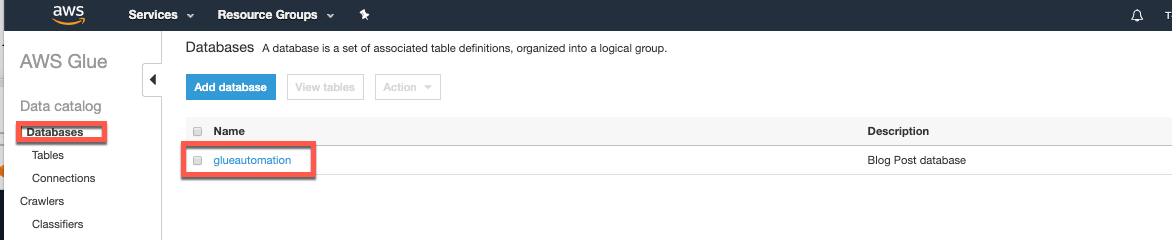
Select Databases and you should see the new database (e.g. glueautomation) created automatically. This name should match the database name that you provided for the CloudFormation stack.
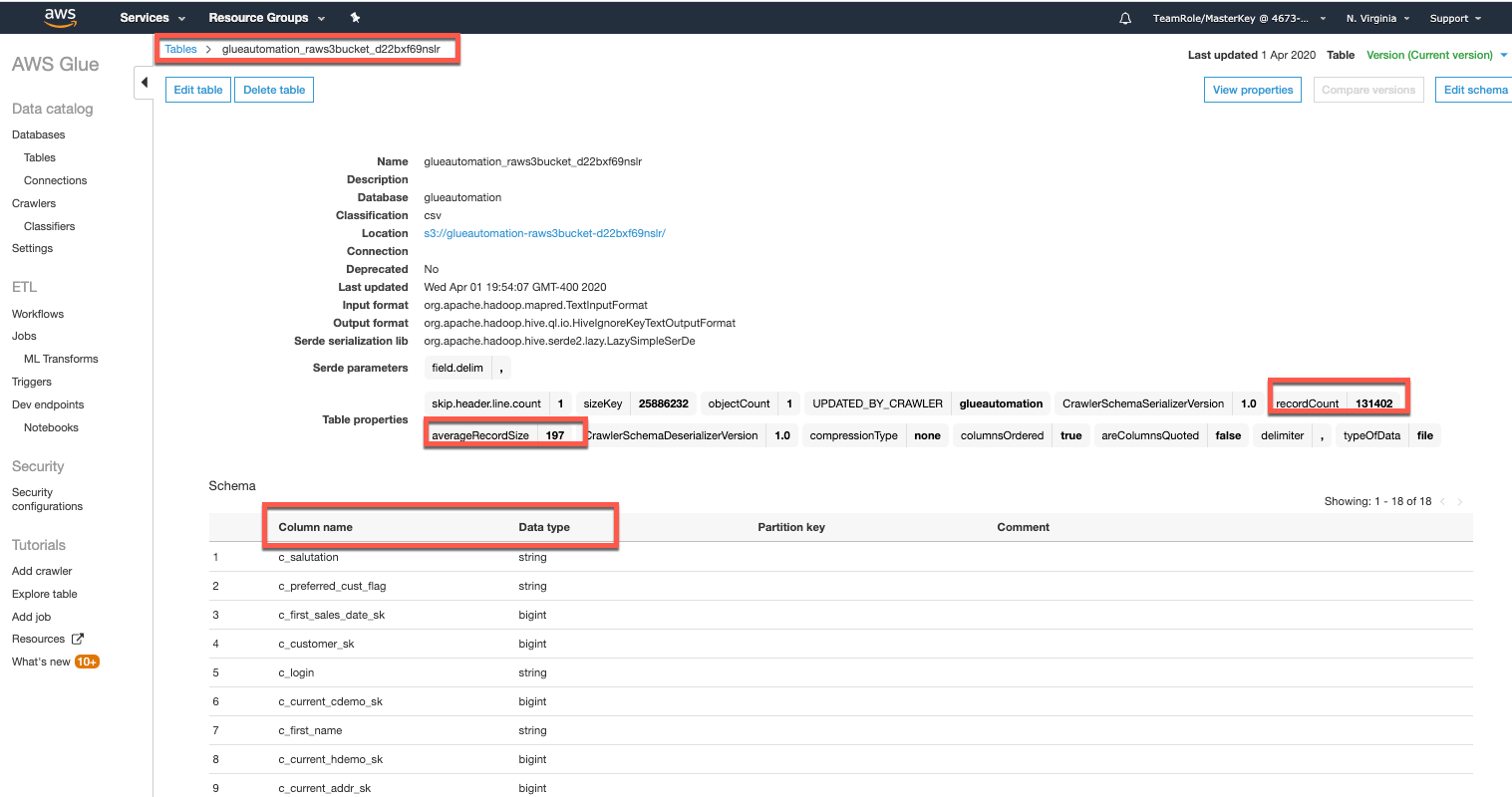
Under Databases select Tables and you will see the new table relating to the file that we copied into the S3 raw bucket. When the Glue crawler was run it was configured to examine files in our S3 Raw Bucket, and it then automatically creates a table in the Glue catalog that is a logical representation of the structure of the file we copied. The crawler automatically provides a name for the table based on the S3 path.

Select the newly created table and review the metadata information automatically gathered by the crawler and populated into the catalog. For example, there is information on the type of file (csv), the S3 location, the average record size, and number of records. The crawler also automatically determines column names and infers the schema of the columns (string, bigint, etc)